







Moving to Markdown

A website update
I'm writing this only for those who follows this blog via RSS feed and probably wonders why they had many notifications on their RSS reader. Sorry, this thing happen when upload a new version of my website. So, what's new on this new website? Not much, nothing changed visually... But everything changed under the hood!
I made a pretty big change: I modified the way article are stored by default by the Content Management System I use: PluXML. I use it to power my blog since more than a decade. Now this one works with markdown files and it wasn't a little task: I had 500 articles created with various WYSIWYG editor and stored as HTML minified and stored into a XML flat files.
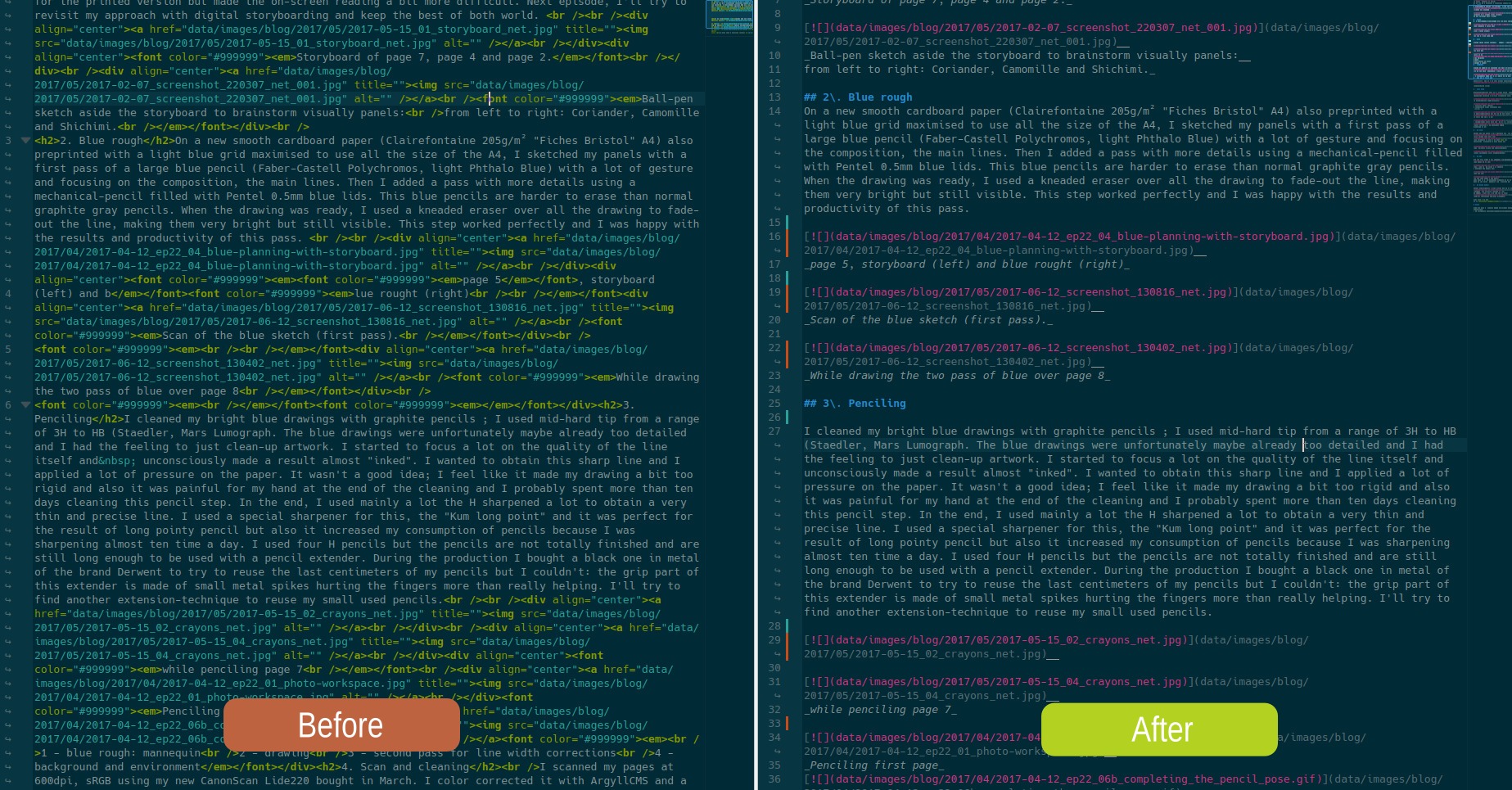
PlxEditor HTML on left VS Markdown on right: this is the same article
Why?
I moved everything to Markdown because all my notes, my Pepper&Carrot scenario, my quick draft, my future tutorials and all my daily interaction on FLOSS project (Phabricator/Gitlab/Github) are revolving around Markdown. I also love the simplicity of this markup language.
For long time, I used a plugin in PluXML named PlxEditor but this one left a lot of extras markup on the way. I had many double empty <em></em>, long chain of <strong></strong>, empty <div>... and so many hazardous other situation happening after copy/pasting. Restructuring a text and moving a picture or moving a title was very tricky. The minified version of this tag soup stored inside an XML file made it even more complex and hard to digest because everything was on a single line. Impossible to read a diff of the file in this conditions. In contrast; while storing the source as markdown, I can perfectly read the diff and track the modifications.
Also, I'm spending a lot of time to edit and maintain my articles (even long time after their publication). That happens mainly thanks to your contributions, readers of my blog, who report me typos, broken links, corrections and improvements. I even have a weekly TO-DO task related to that. If you are interested to help me to correct, proofread, improve my future articles, or just grab a copy of the source; all you have to do now is to hit the gray button Download article source on the footer of each article. With the markdown file in hand, you can correct, edit then send it back to me (by email attachment or pasted online on a temporary pastebin-like service). I'll be now able to see clearly the modification with a tool like Meld that can compare two text files.
How I made this mod for PluXML
I'm writing this technical part here for the PluXML user out there who wonder how I modified PluXML to make this mod. A big part of the convert was done thanks to the Python script found here on the blog of Killian Kemps. Thank you Killian for your blog post, I'm keeping it in my bookmark since probably 2 years... It ran fine on Python3 and I only had to modify a paragraph in parser.py (diff under) to spice the markdown output to the flavor and format I prefer and prevent the output to break links and cut everything to 80 columns:
diff --git a/parser.py b/parser.py
index bfcee1a..17f1f66 100644
--- a/parser.py
+++ b/parser.py
@@ -41,7 +41,13 @@ def parser(post):
local_images_src = [image.get('src') for image in local_images]
# Convert the HTML content to Markdown
- content = html2text.html2text(content)
+ h = html2text.HTML2Text()
+ h.body_width = 0
+ h.protect_links = True
+ h.single_line_break = True
+ h.inline_links = True
+ h.wrap_links = False
+ content = h.handle(content)
else:
:Update: As mentioned in the first comment of this article by Karl Ove Hufthammer, a cleaning upfront before the conversion of the HTML code with Html Tidy could have been a good idea. It's only a sudo apt install tidy away on a Debian based O.S. and works as easily as tidy input.html > output.html ; something really easy and fast to apply to a large folder with a simple Bash loop. I tested it, it fixes a lot of the mistake of PlxEditor and it's a good tip.
Then I erased all the content of <content> tag in the database of article stored on xml ( <content><!\[CDATA\[(?s-i).*\]\]></content> to select the text with a text-editor software like Geany or Kate who can search and replace accross a lot of document with regular expressions). Then I renamed all the markdown files obtained by the Python script (with an app, Gprename) and placed them side by side in the same directory, like that:
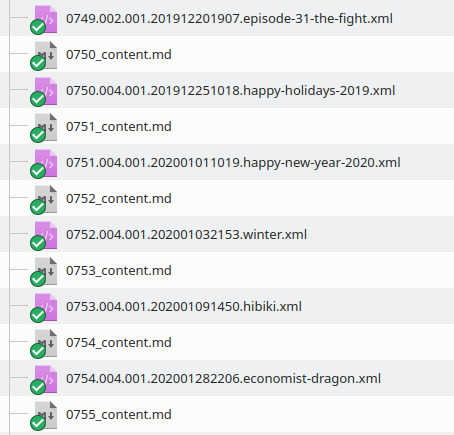
markdown files and xml files side by side
I then modified PluXML to read the content from the markdown file. In core/lib/plx.motor.php, I added this lines around line 692:
$mdfile = PLX_ROOT.$this->aConf['racine_articles'].''.$art['numero'].'_content.md';
$art['content'] = file_get_contents(''.$mdfile.'');Then I modified the full artContent method in core/lib/plx.show.php at line 814 to convert my markdown into html and then display the article thanks to the library https://parsedown.org/; I downloaded it and placed the parsedown.php file into the same directory:
public function artContent($chapo=true) {
include(dirname(__FILE__).'/parsedown.php');
$contents = $this->plxMotor->plxRecord_arts->f('content')."\n";
$Parsedown = new Parsedown();
echo $Parsedown->text($contents));
}At this step, PluXML reads your markdown files as if they were your content and it works everywhere in your templates/theme.
Modifying the mechanism to save the article was a little bit trickier , I had to modify core/lib/class.plx.admin.php at line 976 to add under the definition of the default filename:
$mdfilename = PLX_ROOT.$this->aConf['racine_articles'].$id.'_content.md';Then a little bit later at line 985:
return plxUtils::write($md, $mdfilename);The markdown can also be deleted if you want to use the delete button on the admin panel, in the same class.plx.admin.php locate where PluXML unlink(delete) the article around line 1013 and add that under:
$mdcontentfile = ''.$id.'_content.md';
unlink(PLX_ROOT.$this->aConf['racine_articles'].$mdcontentfile);The file core/lib/class.plx.feed don't normally need tweak, very similar to plxshow , localize where PluXML display $content around line 250 then replace it with something like that:
$mdcontents = $this->plxMotor->plxRecord_arts->f('content')."\n";
$Parsedown = new Parsedown();
contents = $Parsedown->text($mdcontents));That's all. I then added the default plugin plxToolbar and I replaced the css and js of this one with the one of SimpleMd to get a minimal color syntax and a toolbar when I write. You can even customize the css file to get the syntax colored as you prefer.
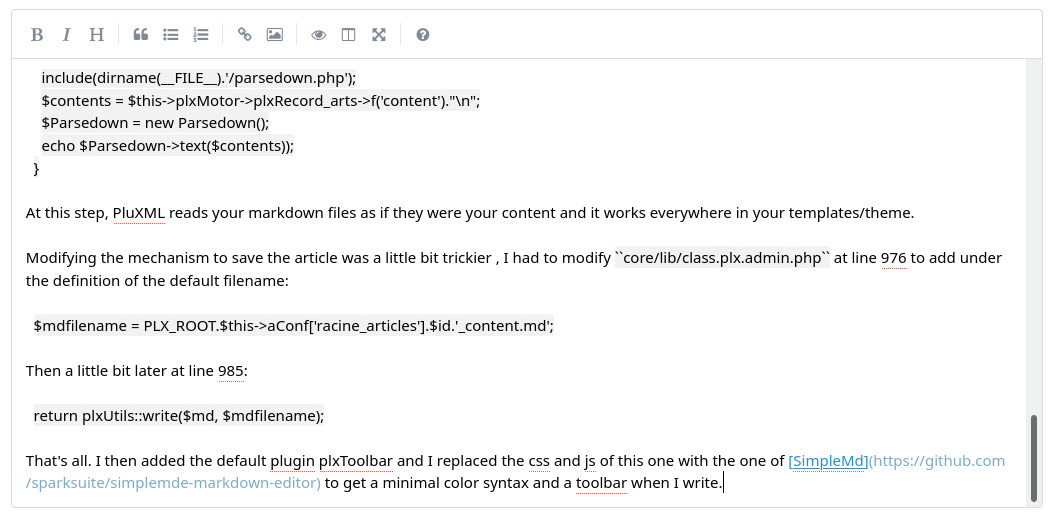
SimpleMd in action while writing this blog-post
A long process
Unfortunately, all wasn't smooth: automation to convert the HTML markup resulted often into many files half broken, links splits over two lines, line break, etc... I tried to solve that with mass search and replace of regex patterns but I couldn't obtain a perfect result. Mainly because the input HTML wasn't really clean in the first place...
So, I still had to review one by one all the article and fix them all manually... Probably that was the part of the process that took the most of time but with over 500 article and an average of a quick 4 min fix per file, 30h are quickly spent... That's the charm of getting a blog since a long time and managing a digital past.
Fortunately, cleaning markdown with a colored syntax is a solid process: I could focus on the structure of the content and I was sure the rendering would be fine. I had no surprise and I really had a What You Mean is What you Get experience.
To be released soon
So what will be the benefit of this time investment? This change will allow me to release two bigger than usual articles I have as draft:
Production Report: Book project, Part.3:
This article is around the corner and will be the result of all my experimentation and conclusion about the Mini-Books project. I'm still waiting the last Mini-Book 5 print proof in my mailbox.
A guide to install my GNU/Linux system
I'm really happy with all the install guide I wrote over the last ten years; but I had hard time to digest the regressions of the GNU/Linux dekstop for artist over the last five years and I did stop to write them... But I decided to do it again because it was useful. The guide will be based on Kubuntu 19.10 with an evolution to 20.04LTS in April.
That's all, I for sure have more ideas but that will be for later.

14 comments
I guess this suggestion is a little late, but for cleaning up your old HTML code, you could have used HTML Tidy (http://www.html-tidy.org/). A very nice tool, originally created by one of the editors of the HTML specifications.
Hey Karl! Thank you for the suggestion; I tried. It's as simple as a "sudo apt install" tidy then "tidy input.html > output.html" and it is a good tip. I see a good improvement over an HTML soup of PlxEditor (with the default option, so maybe it can be better with fine tuning). But no regret; I also saw the issue on the markup were still here; mainly because a lot are issue not in the markup structure but also in the information itself (getting a linebreak in em, having all h2 titles strong, I also used a lot strong as a subsitute for h3 or h4 titles ). Even with this tip, the manual pass of fix would have been necessary. But certainly easier! I'll add it into the DIY part of the article in case a future PluXML user wants to save time. Thank you for the good tip!
I understood very little of this, BUT: I'm excited to find out by chance why sometimes my RSS feed has a pile of duplicates of old notifications from various blogs I follow :D Yours didn't happen, though. Only this post was in my feed.
Oh, thank you @Oros for the feedback! I also changed the way I upload changes to try to simplify the way I maintain things on the website. (In short: before I used manual drag&drop with FileZilla, and now I made a Bash script based on Rsync and SSH. This last one probably preserve timestamp of file creation or something like that.) Another guess: the RSS reader are better and better and know now how to keep the article already read as read, even if their code, timestamp, change slightly.
I didn't get any duplicate articles in my feed reader (tiny tiny rss), however in its article view everything in centered, which makes the code snippets look a bit odd.
Thank you Ingo! I could check thanks to the online demo of Tiny Tiny Rss and it was a bug of my Feed; I had a unclosed div element with a div aligned at center for the top image. I also could see another interpretation of the html code; the one from Mozilla (reading the RSS directly in browser) and the one of Tiny Tiny Rss; it was uselful to correct little details here and there. Something I couldn't see before your comment, thank you!
My level of computer proficiency kind of ends at operating the device (which luckily includes operating a linux computer with in a bash, Windowmaker or KDE environment) and visiting the internet (and watching your beautiful work). However I just came here to say that I really love that drawing of the little witch in the article. It is a cool perspective and I think the kind of rough drawing makes it just enough "real" without resorting to the canvas texture. I like it.
Obviously I love every new episode of Pepper and Carrot and it doesn't hurt at all to be supporting you. Actually I feel that that the information, instructions, lessons, brushes and everything you're giving in your blogs are well worth some money too. There may be a place for another level of Patron where we also donate when you release another lengthy blog article. Maybe not the same kind of money that goes with a full episode, but definitely something. Of course I also understand that you would feel pressure on yourself for delivering quality blogs now too even though I just want to say that the quality is already right up there. And you're clearly putting time and effort in these. So yeah at the end of the day of course it will be your decision whether or not to offer the option but I just wanted to drop the suggestion.
By curiosity, is there any reason for using PluXml instead of some static site generator like Hugo for example ? (More static site gen here: https://www.staticgen.com/ but Hugo is probably one of the simplest one to use).
From what I understand PluXml requires you to have a php server, and for your usage you have to convert markdown to html. With a static site gen you could host your website on github/gitlab and have markdown rendered out of the box.
Hey, that's a good question; but static website rarelly have the features I like:
1. A way to author new blog-post easily via a smartphone or any computer with a webbrowser and a password.
2. A comment system (migrating 10K comments would be hard, imo).
3. This blog runs with the same type of URL since 2004. I can't imagine changing them and impact it would have on referencing.
Also, refactor all from scratch for anything is often the worst decision :-) I prefer to extend what I know that runs fine. Especially when I have this traffic.
Thank you Vinay! Thank you for noticing the little artwork ;) I'm working on improving this style; a grayscale to color technique with a painterly feel (but no canvas texture anymore).
That's also very nice what you wrote about the patronage of the blog post. I'm trying right now to pack this time within the production of episodes. I'll keep trying to research how to make episode happening more frequently, that's imo the real way for me to improve my budget.
good move, I've been writing all my posts and pages since 2014 (converted from WordPress then, all the WordPress posts are .wp (html)).
every have a go with some of the more popular static site generators such as Hugo?
**in markdown
Hey, read my answer to Laurent NOEL; I think I replied already to the same question :)
Good movie
Post a reply
The comments on this article are archived and unfortunately not yet connected to a dedicated post on Mastodon. Feel free to continue the discussion on the social media of your choice. Link to this post:You can also quote my account so I'll get a notification.
(eg. @davidrevoy@framapiaf.org on my Mastodon profile.)